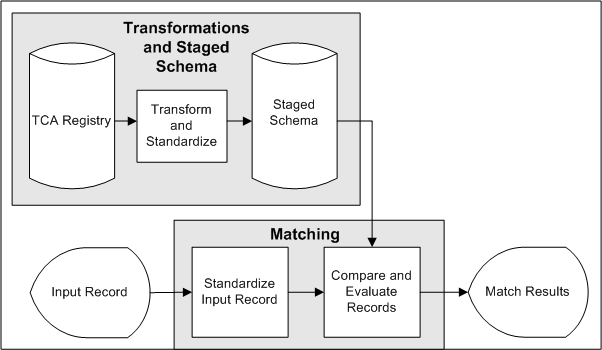
This diagram illustrates how the different features of Data Quality Management work together to find matches and duplicates.
The TCA Registry contains party information that could have been entered with typographical errors, spelling errors, and aliases.
You run the DQM Staging program to transform and standardize the attribute values, such as party name and number, in a copy of the Registry, the staged schema. The attributes to include in the schema, as well as the transformations to use on each attribute, are defined in the Define Attributes and Transformations page.
The staged schema stores the transformed attribute values, separate from the original Registry.
Input records come in when you enter or search for party information, or run a duplicate identification process.
The transformations in a match rule transform the attribute values in the input record.
The same match rule is applied to compare the transformed input record attributes against the attributes in the staged schema.
Based on how the attributes match up, potential matches from the staged schema are identified for the input record. If the match rule contains scoring criteria, the selected records from the staged schema are also scored.
Bulk duplicate identification is a particular DQM process to identify duplicates for a large number of records within the TCA Registry. The process involves:
B-Tree indexes in the staged schema.
Match rules with the Bulk Duplicate Identification purpose, which include acquisition attributes and transformations that are defined for bulk duplicate identification.
Instead of comparing against the staged schema one at a time for each input record, as with simple duplicate identification, bulk duplicate identification compares the whole set of input records at once through a join procedure in the staged schema.
This diagram illustrates the bulk duplicate identification process:
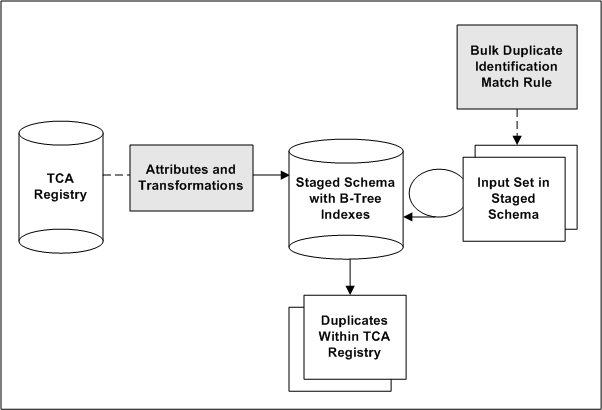
TCA Registry attributes are transformed for the staged schema. The attributes to include in the schema, as well as the transformations to use on each attribute, are defined in the Define Attributes and Transformations page.
Also defined are the attribute and transformation combinations to be used for bulk duplicate identification. The staged schema includes B-Tree indexes only for the transformed attributes marked for bulk duplicate identification.
A duplicate identification process is started, either for a subset of records in the TCA Registry or for the entire Registry. The transformed version of that set of input records is already represented in the staged schema.
A match rule with the Bulk Duplicate Identification purpose is applied, and the input set within the staged schema is joined with the staged schema.
Each record in the input set is simultaneously compared against all other records in the same staged table using only B-Tree indexes.
Based on how the attributes match up, potential duplicates from the staged schema are identified. If the match rule contains scoring criteria, the selected records from the staged schema are also scored.
