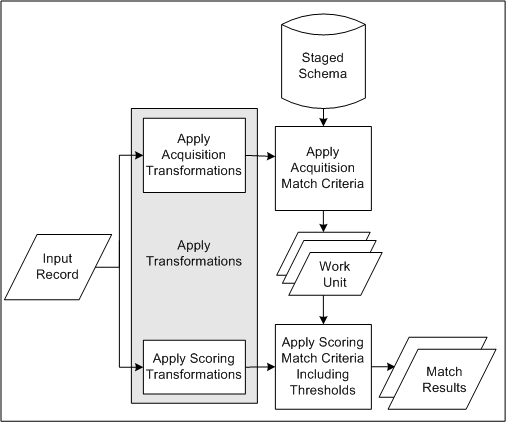
This diagram describes the DQM matching process involving match rules with the Expanded Duplicate Identification purpose.
The staged schema stores the transformed TCA Registry attribute values for comparison in the matching process. The included attributes and the transformations applied to each are defined in the Define Attributes and Transformations page.
Input records come in when you enter party information, or run a duplicate identification process.
Transformations from the acquisition and scoring phases of the match rule transform the input record, one entity at a time, for the attributes defined in the match rule.
The attribute values in the input record that are transformed by the acquisition transformations in the match rule are compared against the attribute values in the staged schema.
Matched acquisition attribute values determine the most relevant subset of records from the staged schema to form the work unit.
The work unit consists of all records from the staged schema with attribute values that match the transformed acquisition attribute values of the input record.
The work unit saves you time and resources because this relevant subset of records, not the entire staged schema, can be compared against the input record for scoring.
The attribute values in the input record that are transformed by the scoring transformations in the match rule are compared against the attribute values in the work unit. Based on the match rule, a score is calculated for each record in the work unit.
Steps 3 through 6 are repeated for each entity.
Scores from all entities are added together for each record.
The score of each work unit record is compared against the match and Automerge thresholds defined in the match rule.
Records with scores that reach the match threshold are selected as matches for the input record.
Records with scores that also reach the Automerge threshold are automatically merged if Automerge is implemented and the match rule is designated for use with Automerge.
