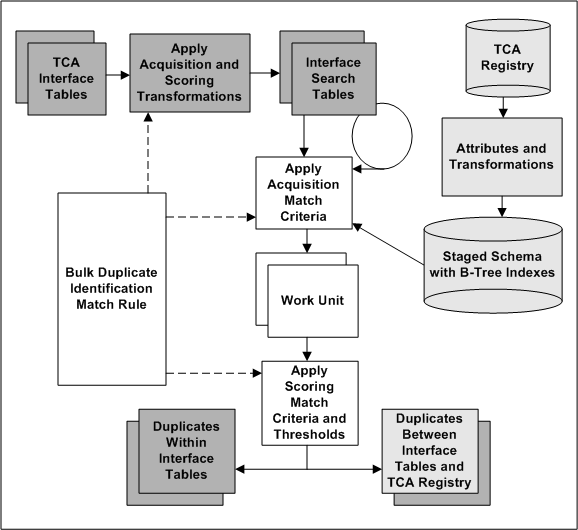
The batch and Registry de-duplication are separate processes that run at different times, either with the same or different match rules. For illustration purposes, this diagram describes both de-duplication processes:
TCA Registry attributes are transformed for the staged schema. The attributes to include in the schema, as well as the transformations to use on each attribute, are defined in the Define Attributes and Transformations page.
Also defined are the attribute and transformation combinations to be used for bulk duplicate identification. The staged schema includes B-Tree indexes only for the transformed attributes marked for bulk duplicate identification.
The user specifies a match rule with Bulk Duplicate Identification purpose for the de-duplication.
When the de-duplication process starts, the acquisition and scoring transformations are applied to the attributes in the interface tables, based on the selected match rule.
The transformed interface table records are mapped and loaded into the interface search tables, a set of temporary staged tables with B-Tree indexes.
HZ_SRCH_PARTIES
HZ_SRCH_PSITES
HZ_SRCH_CONTACTS
HZ_SRCH_CPTS
To find duplicates within the TCA interface tables:
The interface search tables are joined with themselves.
The acquisition match criteria of the same match rule is applied to compare each record against all other records in the same staged table simultaneously.
For example, an acquisition criterion is the D-U-N-S Number attribute with the Exact transformation. All D-U-N-S Numbers, as transformed by the Exact transformation, would be compared against one another.
To find duplicates between the TCA interface tables and the TCA Registry:
The interface search tables are joined with the staged schema. The two sets of staged tables have the same columns. This table shows the mapping between the interface search and staged schema tables:
| Entity | Interface Search Table | Staged Schema Table |
|---|---|---|
| Party | HZ_SRCH_PARTIES | HZ_STAGED_PARTIES |
| Address | HZ_SRCH_PSITES | HZ_STAGED_PARTY_SITES |
| Contact | HZ_SRCH_CONTACTS | HZ_STAGED_CONTACTS |
| Contact Point | HZ_SRCH_CPTS | HZ_STAGED_CONTACT_POINTS |
The acquisition match criteria of the same match rule is applied to compare all records in each interface search table against all records in the staged schema using only B-Tree indexes.
Matched acquisition attribute values determine the most relevant subset of records from the interface search tables to form the work unit.
Using the scoring criteria in the match rule, each record in the work unit is compared to all other work unit records in the same staging table.
A score is calculated for each record in the work unit, and scores for all entities are added together for determining duplicate parties.
The score of each work unit record is compared against the match and automatic merge thresholds defined in the match rule.
Records with scores above the match threshold are selected as potential duplicates and resolved accordingly.
For Registry de-duplication, records with scores that also exceed the automatic merge threshold are automatically merged after import, if the match rule is allowed for Automerge.
